
Why Old LLM Systems Waste GPU Memory and How vLLM Fixes It

When people talk about running Large Language Models (LLMs), they usually focus on GPUs.
But the real performance problem is often memory usage, not compute.
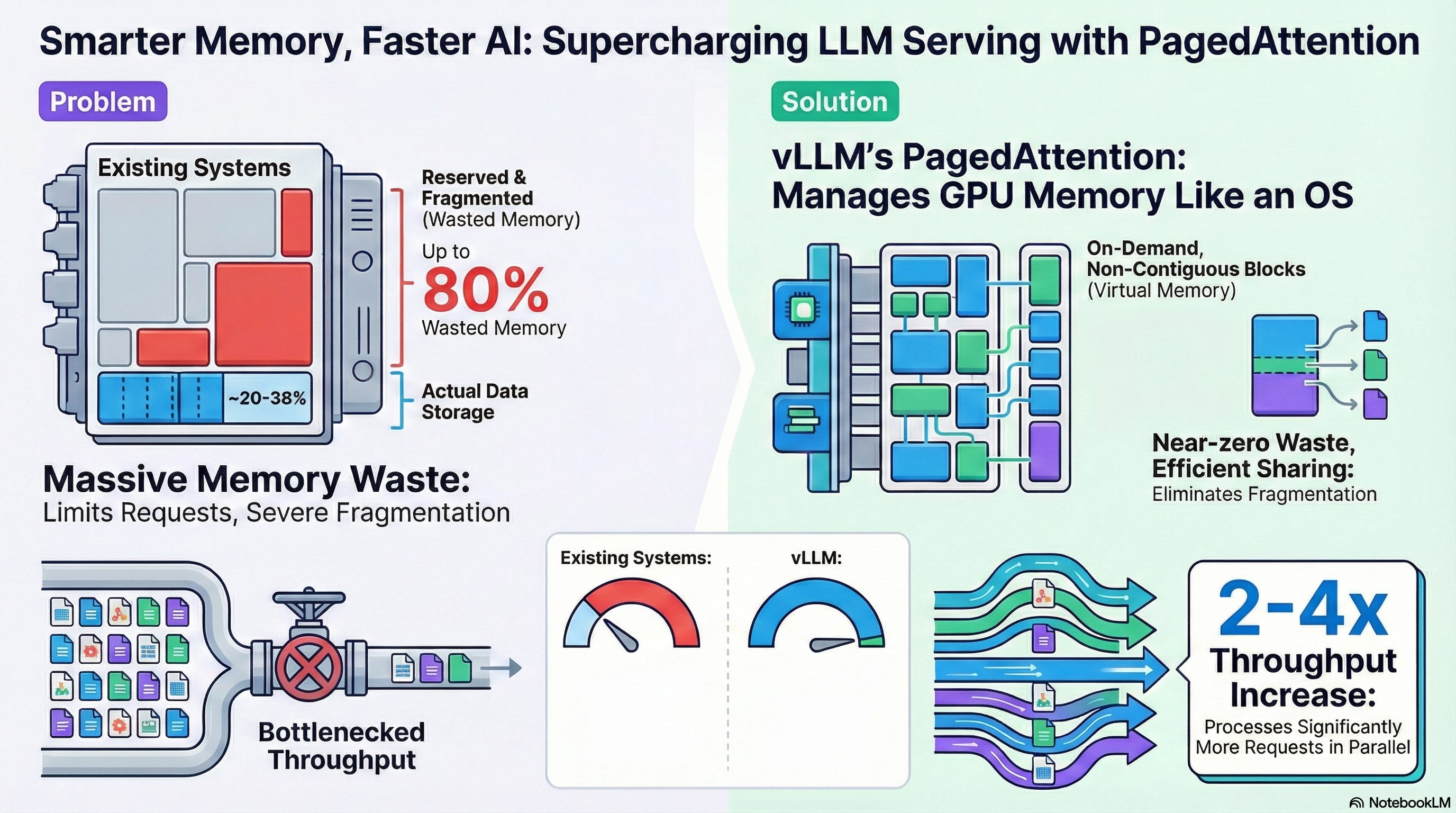
The Big Problem: GPU Memory Is Wasted
When an AI model starts generating text, it does not know in advance how long the answer will be.
Older systems handle this badly:
They reserve a large chunk of GPU memory upfront
This memory is reserved “just in case” the response is very long
Most responses are short, so a large part of that memory stays empty
In many cases, up to 80% of GPU memory is wasted.
Think of it like this:
You book a 10-seat table for 2 people,
and no one else is allowed to sit there, even though most seats are empty.
Because of this:
GPUs can run fewer requests at the same time
Systems become slow and bottlenecked
Expensive GPU resources are underused
The Smart Solution: vLLM’s PagedAttention
vLLM fixes this problem by changing how GPU memory is managed.
Instead of reserving one big memory block, vLLM:
Breaks memory into small blocks (called pages)
Uses memory only when it is actually needed
Adds more blocks only if the response becomes longer
This is very similar to how modern operating systems manage RAM.
Because memory is flexible:
There are no large empty gaps
Memory fragmentation is reduced
GPU memory is used efficiently
The Result: Faster and Cheaper LLM Inference
When memory waste is removed:
More requests can run in parallel
GPUs handle 2× to 4× more workloads
Throughput increases without adding more hardware
Same GPUs. Much better performance.
vLLM’s PagedAttention shows that better memory management alone can unlock massive performance gains.
Sometimes, the biggest speedups come not from more power—but from less waste