
Why LLM Inference Costs More Than Training
What Can You Do About It? Read if you want to save Inference Cost

Most people think the biggest cost in building AI models is the training part.
After all, training a model like GPT-4 can cost up to $200 million!
But here’s the surprising truth:
Running AI models (inference) over time costs much more than training them once.
In fact, inference can make up 80-90% of the total cost of using an AI model.
Let’s break down why that happens.
Training vs. Inference: What’s the Difference?
Training = One-Time Investment
Training an AI model is like teaching it everything it needs to know.
It requires:
Thousands of powerful GPUs (costing ~$30,000+ each)
Huge amounts of Electricity
Skilled Engineers
Processing and storing massive amounts of data
Examples of training costs:
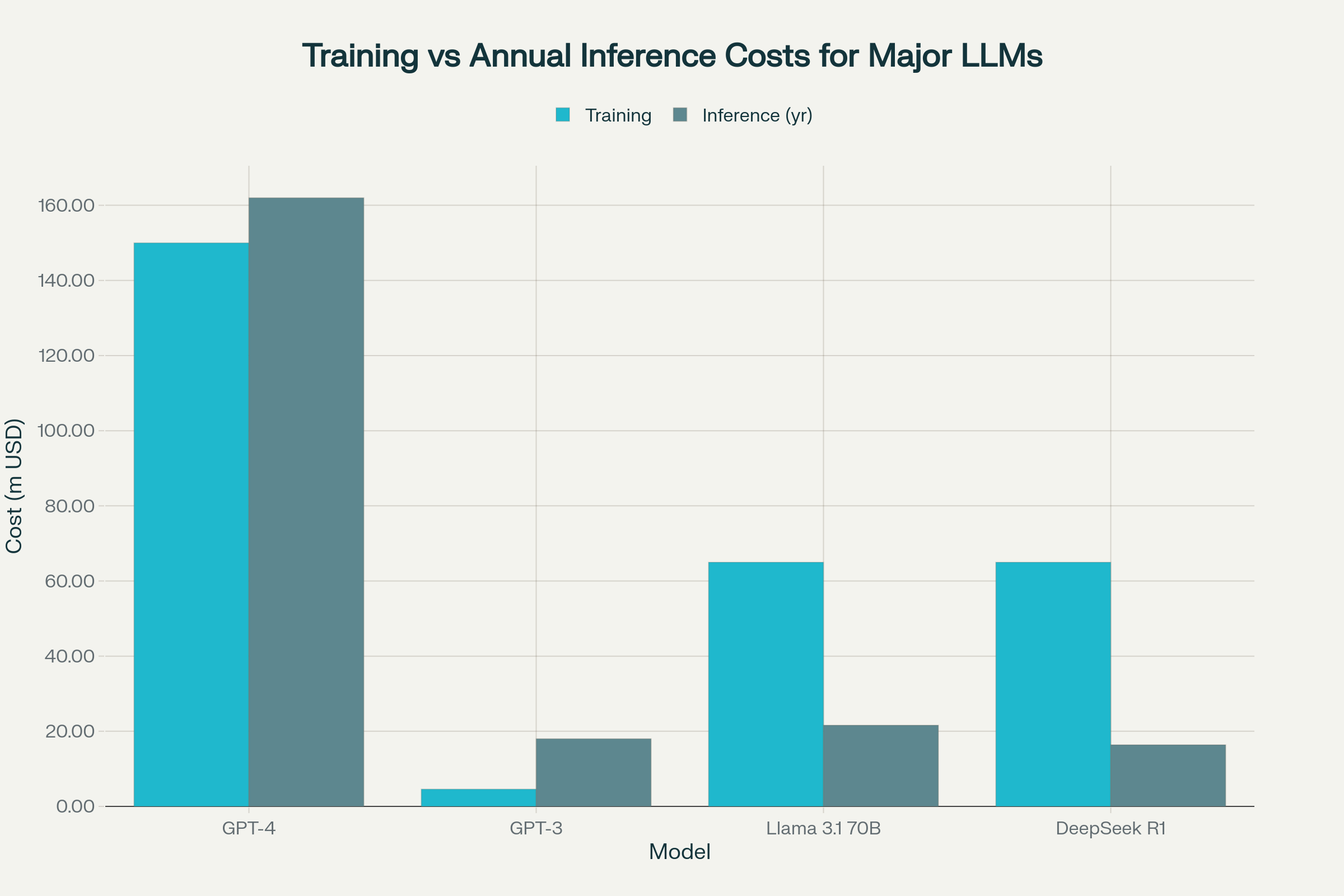
GPT-4: ~$100–200 million
LLaMA 3.1 70B: ~$50–80 million
GPT-3: ~$4.6 million
But once trained, the model doesn’t need to be trained again frequently.
Inference = Ongoing, Daily Cost
Inference is when people use the AI, asking questions, getting answers, writing code, summarizing text, etc.
This happens every minute, every hour, every day.
So even though each interaction may cost a few cents, they add up fast. For example:
GPT-4: $13.50 per million tokens (words+symbols)
Claude 3 Opus: $15 per million tokens
Why Inference Is So Expensive
It never stops: AI models serve millions of queries every day.
Token-based billing: Every input/output token is charged.
It needs fast, powerful hardware: Even short delays can frustrate users.
Memory demands: Each answer needs space to store “context” from the conversation.
A company chatbot that handles 6 million tokens per month/user already costs ~$90. Now scale that to thousands of users, and the bills become huge.
Technical Problem: KV Cache Explosion
When you chat with an AI model, it stores “key-value” (KV) pairs to remember past tokens.
But:
These KV caches grow bigger with longer responses.
They use a lot of GPU memory.
Serving many users at once makes the problem worse.
For example, LLaMA-2 13B needs ~1MB of memory per output token, and that adds up fast!
The Fix: LMCache + vLLM
To solve this, engineers built LMCache, a smart system that reduces inference costs by managing KV caches better.
It works beautifully with vLLM, an efficient AI inference engine.
How LMCache Helps
Reuses old answers: Instead of just caching prefixes; it reuses any repeated content across users and sessions.
Uses multiple layers of memory: GPU, CPU, and even disk. This massively increases usable memory.
Moves data efficiently: Uses CUDA (NVIDIA's tech) to speed up memory transfer with zero-copy tricks.
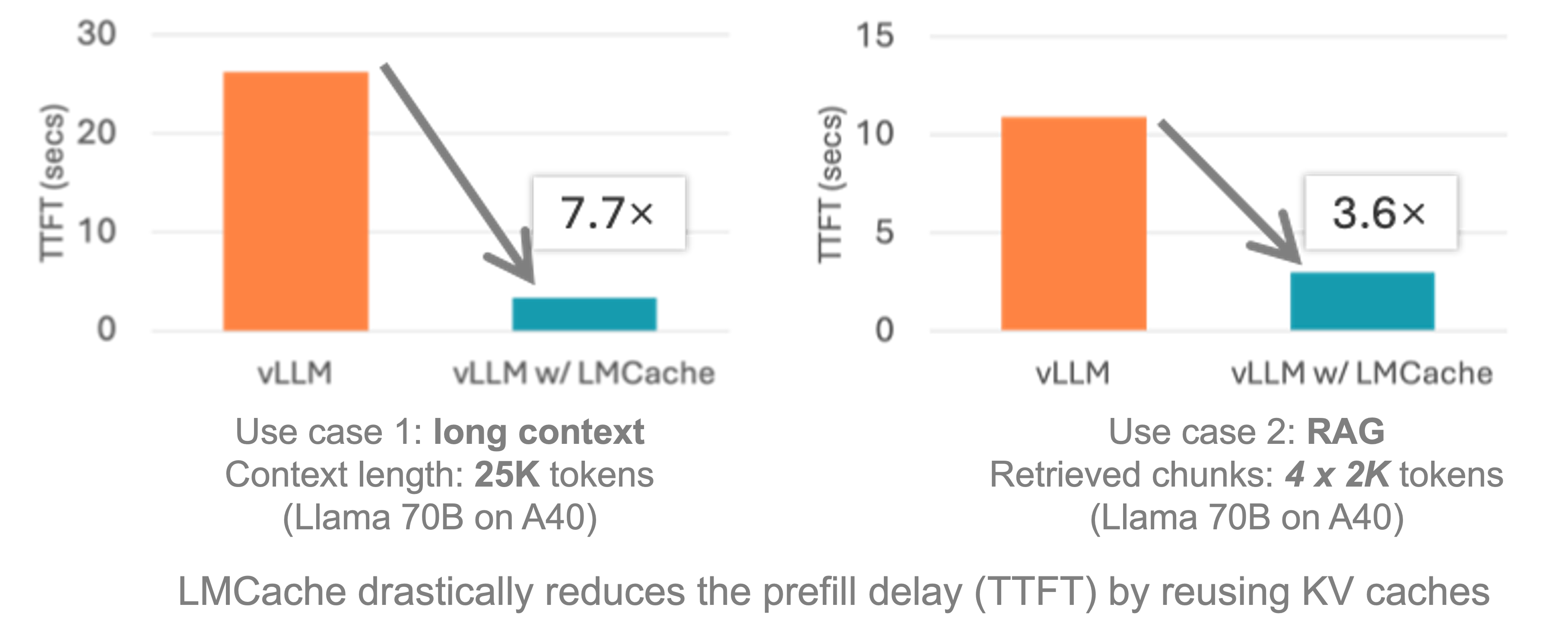
How Much Better Is It? Real Results
Companies using vLLM + LMCache report 50–90% lower GPU costs
Speed
Time to First Token (TTFT): Down from 28s → 3.7s
Latency: 78.8% lower wait times between tokens
Memory
50% lower GPU memory use due to smart offloading
Cache Reuse
60%+ hit rate for reused content (like repeated questions or docs)
Throughput
Can handle 3–10× more users with the same hardware
Cost Savings
Companies using LMCache report 50–90% lower GPU costs
Self-Hosting vs. API: When Does It Make Sense?
If you’re a startup using small amounts of AI (less than 100 million tokens/month), using APIs like OpenAI is fine.
But if your usage grows:
At 1 billion tokens/month, GPT-4 API costs ~$13,500/month
Self-hosting LLaMA 70B with LMCache costs ~$872–$8,720/month
Savings: up to 93%
Looking Ahead:
As models grow larger and more advanced:
Inference will keep getting more expensive
Real-time AI will become the norm
Businesses will demand faster and cheaper AI systems
That’s why inference optimization matters more than ever.
Final Thoughts
Training might grab the headlines, but inference is where the real costs are. And for AI to scale sustainably, we need smart, efficient systems.
LMCache + vLLM offers exactly that, cutting costs, improving speed, and unlocking scalability for AI in the real world.
If you’re building or running AI products, now’s the time to rethink your inference stack.
Source: LinkedIn